Busting Big Data
Verfasst: 4. Mai 2018, 17:32
Dieser Thread wird mir in den nächsten Wochen dazu dienen, die Grundlagen von Big Data zu erarbeiten und gezielt nach Schwächen dieses Konzeptes zu suchen, dass sich in jeder fünften Stellenanzeige für Technomathematiker findet.
Dabei scheinen die meisten nicht zu bemerken, dass Big Data im wesentlichen auf dem Positivismus zu beruhen scheint, weswegen ich auch der Meinung bin, dass das Konzept beträchtliche Macken haben müßte.
Ersteinmal findet sich unter http://datasciencemasters.org/
ein Onlinekurs für Big Data.
Hab ich mehr oder weniger alles schonmal an der Uni gemacht, vielleicht nicht ganz so ausführlich, die mathematischen Grundlagen sind easy, das Computerzeug ist schon ein bisschen schwerer. Soweit ich es überblicken kann hat es nicht ganz so viel mit Programmieren zu tun, dass ist schonmal gut. Es geht also primär um Theorie.
Hier ein pdf über die Anwendung von Big Data beim google-Algorithmus. Das sind aber wirklich nur die Grundlagen.
Es geht darum, dass google die Webpages und ihre Verweise aufeinander in Form eines Graphen speichert, der wiederum in Form einer Matrix darstellbar ist.
Wenn nun ein User zufällig durchs Internet surfed und Links anklickt, kann man sein Verhalten als Markowkette darstellen. Dabei sind die Knotenpunkte Webpages, die Pfeile haben Wahrscheinlichkeiten, mit denen der User auf Links klickt und zu anderen Seiten wechselt.
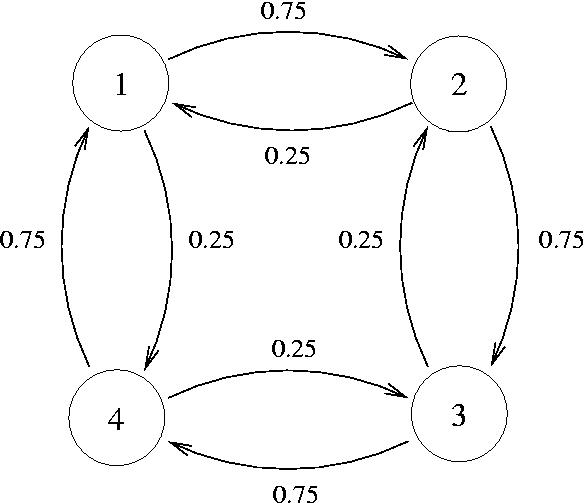
Ziel ist es nun, eine geordnete Liste aller Websites zu erstellen, dem sogenannten Page Rank. Je häufiger andere Websites auf eine Website verweisen, desto höher steht sie im Ranking. Und das färbt dann auch auf die Websites ab, auf die sie verweisen. Damit das nicht ausartet (also Websites sich gegenseitig ins unendliche Steigern), gibt es einen eingebauten Dämpfer.
Nun wird das zufällige Surfen solange iteriert, bis sich sich eine Art Gleichgewicht einstellt, also der Rang der Links von Website zu Website objektiv erkannt ist. Das dieses Gleichgewicht existiert lässt sich mathematisch beweisen. Nun haben wir die Zielmatrix, wir benötigen aber eine geordnete Liste.
Gesucht ist also nun der Eigenvektor mit Eigenwert 1 dieser Matrix (im Bild unten A), dieser ist dann die geordnete Liste, die wir suchen.
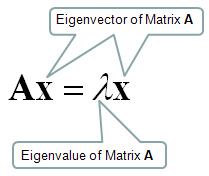
Der Grund ist einfach der, dass der Eigenvektor mit Eigenwert 1 quasi einen neutralen Beoachter wiederspiegelt, der nach einer gleichverteilten Wahrscheinlichkeit Websites ansurfed oder aber auf einer Website die vorhandenen Links mit gleich großer Wahrscheinlichkeit klickt.
Wenn aber dieses Verhalten an den Tag gelegt wird, werden eben die Seiten am schnellsten gefunden, die die meisten Verweise auf sich hat, beziehungsweise Verweise von Verweisen and so on. Genau das repräsentiert ja der PageRank. Dies soll unabhängig von der Startposition des zufälligen Surfers gelten, weswegen wir zuerst das Gleichgewicht ermitteln mußten.
Am Ende gibt es noch ein paar Ideen bezüglich Speicheroptimierung. Google benötigt ein paar Stunden und ein paar Tausend Rechner, um den Page Rank auszurechnen. Das passiert in unregelmäßigen Zeitabständen, zwischendurch sammeln die Crawler die notwendigen Infos.
Die geordnete Liste die letztlich ausgegeben wird muß dann natürlich noch mit dem Suchwort kombiniert werden. Dies ist aber nicht Thema des Skriptes.
Das ist wirklich nur das Grundgerüst, inzwischen gibt es 200 Faktoren anhand derer google Websites bewertet.
edit: fragt ruhig, wenn etwas unklar ist.
Dabei scheinen die meisten nicht zu bemerken, dass Big Data im wesentlichen auf dem Positivismus zu beruhen scheint, weswegen ich auch der Meinung bin, dass das Konzept beträchtliche Macken haben müßte.
Ersteinmal findet sich unter http://datasciencemasters.org/
ein Onlinekurs für Big Data.
Hab ich mehr oder weniger alles schonmal an der Uni gemacht, vielleicht nicht ganz so ausführlich, die mathematischen Grundlagen sind easy, das Computerzeug ist schon ein bisschen schwerer. Soweit ich es überblicken kann hat es nicht ganz so viel mit Programmieren zu tun, dass ist schonmal gut. Es geht also primär um Theorie.
Hier ein pdf über die Anwendung von Big Data beim google-Algorithmus. Das sind aber wirklich nur die Grundlagen.
Es geht darum, dass google die Webpages und ihre Verweise aufeinander in Form eines Graphen speichert, der wiederum in Form einer Matrix darstellbar ist.
Wenn nun ein User zufällig durchs Internet surfed und Links anklickt, kann man sein Verhalten als Markowkette darstellen. Dabei sind die Knotenpunkte Webpages, die Pfeile haben Wahrscheinlichkeiten, mit denen der User auf Links klickt und zu anderen Seiten wechselt.
Ziel ist es nun, eine geordnete Liste aller Websites zu erstellen, dem sogenannten Page Rank. Je häufiger andere Websites auf eine Website verweisen, desto höher steht sie im Ranking. Und das färbt dann auch auf die Websites ab, auf die sie verweisen. Damit das nicht ausartet (also Websites sich gegenseitig ins unendliche Steigern), gibt es einen eingebauten Dämpfer.
Nun wird das zufällige Surfen solange iteriert, bis sich sich eine Art Gleichgewicht einstellt, also der Rang der Links von Website zu Website objektiv erkannt ist. Das dieses Gleichgewicht existiert lässt sich mathematisch beweisen. Nun haben wir die Zielmatrix, wir benötigen aber eine geordnete Liste.
Gesucht ist also nun der Eigenvektor mit Eigenwert 1 dieser Matrix (im Bild unten A), dieser ist dann die geordnete Liste, die wir suchen.
Der Grund ist einfach der, dass der Eigenvektor mit Eigenwert 1 quasi einen neutralen Beoachter wiederspiegelt, der nach einer gleichverteilten Wahrscheinlichkeit Websites ansurfed oder aber auf einer Website die vorhandenen Links mit gleich großer Wahrscheinlichkeit klickt.
Wenn aber dieses Verhalten an den Tag gelegt wird, werden eben die Seiten am schnellsten gefunden, die die meisten Verweise auf sich hat, beziehungsweise Verweise von Verweisen and so on. Genau das repräsentiert ja der PageRank. Dies soll unabhängig von der Startposition des zufälligen Surfers gelten, weswegen wir zuerst das Gleichgewicht ermitteln mußten.
Am Ende gibt es noch ein paar Ideen bezüglich Speicheroptimierung. Google benötigt ein paar Stunden und ein paar Tausend Rechner, um den Page Rank auszurechnen. Das passiert in unregelmäßigen Zeitabständen, zwischendurch sammeln die Crawler die notwendigen Infos.
Die geordnete Liste die letztlich ausgegeben wird muß dann natürlich noch mit dem Suchwort kombiniert werden. Dies ist aber nicht Thema des Skriptes.
Das ist wirklich nur das Grundgerüst, inzwischen gibt es 200 Faktoren anhand derer google Websites bewertet.
edit: fragt ruhig, wenn etwas unklar ist.

