Mjam, Pekingenten û¥berall.
https://foreignpolicy.com/2018/11/16/ch ... isnt-real/
Busting Big Data
-
Franz_Nord

- Verteidiger des wahren BlûÑdsinns|Verteidiger des wahren BlûÑdsinns|Verteidigerin des wahren BlûÑdsinns
- BeitrûÊge: 98
- Registriert: 17. Juni 2018, 15:59
- Disorganisation: Chaos-Kult, Kabale der lachenden GûÑttin
Re: Busting Big Data
Erster Fnord der [color=#FFFF00][font=Consolas]Kabale der lachenden GûÑttin[/font][/color]
Erster HûÊretiker des Chaos Kults
Fnordmeister von Schloss Gammelot und Erster der Krempelritter der Tafelecke
Erster HûÊretiker des Chaos Kults
Fnordmeister von Schloss Gammelot und Erster der Krempelritter der Tafelecke
-
fehlgeleitet

- Ausgetreten|Ausgetreten|Ausgetreten
- BeitrûÊge: 2774
- Registriert: 15. November 2015, 18:04
Re: Busting Big Data
danke fû¥r diesen aufklûÊrerischen artikel, der schlûÊgt ja in meine kerbe 
"Die Lehre vcn Marx ist allmûÊchtig, weil sie wahr ist" (Lenin)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
-
LordCaramac
- Schlandmeisterin|Schlandmeister|Schlandmeisterin
- BeitrûÊge: 525
- Registriert: 21. Dezember 2010, 03:38
- Disorganisation: St Yogi Bear Cabal
Re: Busting Big Data
Mein autoritûÊr-marxistischer Ex-Mitbewohner findet ja immer noch China ganz groûartig und wû¥rde sich wû¥nschen, die ganze Welt tûÊte sich China anschlieûen, weil seiner Ansicht nach nur eine harte sozialistische Weltdiktatur diese Zivilisation noch vor dem Untergang retten kann...
-
Bwana Honolulu

- Hausmeistens|Hausmeister|Hausmeisterin
- BeitrûÊge: 12212
- Registriert: 8. September 2010, 10:10
- Disorganisation: Aktion 23, Zimmer523, GEFGAEFHB, ddR, Fractal Cult, EHNIX, The ASSBUTT
- Wohnort: leicht verschoben
- Pronomen: er/ihm
- Kontaktdaten:
Re: Busting Big Data
Inkonsequent. Dann soll er lieber auf das Modell Nordkorea setzen. 
Wenn ich schon der Affe bin, dann will ich der Affe sein, der dem Engel auf's Maul haut. 
ããÇã°ã ãÇÆˋã°ò!
Seine Quasarische SphûÊrizitûÊt, der Bwana HonoluluããÇã°ã ãÇÆˋã°ò!
 ,
,ûberbefehlshabender des Selbstmordkommandos öˋã,
Herrscher û¥ber alles, alles andere und wieder nichts,
Urgroûpapapapst und Metagottkaiser in Zimmer523,
Grand Admirakel der berittenen Marinekavallerie zur See,
Reichsminister fû¥r Popularpodicifikation,
Hû¥ter des Heiligen Q.
-
fehlgeleitet
- Ausgetreten|Ausgetreten|Ausgetreten
- BeitrûÊge: 2774
- Registriert: 15. November 2015, 18:04
Re: Busting Big Data
DKP?LordCaramac hat geschrieben:Mein autoritûÊr-marxistischer Ex-Mitbewohner findet ja immer noch China ganz groûartig und wû¥rde sich wû¥nschen, die ganze Welt tûÊte sich China anschlieûen, weil seiner Ansicht nach nur eine harte sozialistische Weltdiktatur diese Zivilisation noch vor dem Untergang retten kann...
"Die Lehre vcn Marx ist allmûÊchtig, weil sie wahr ist" (Lenin)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
-
Bwana Honolulu
- Hausmeistens|Hausmeister|Hausmeisterin
- BeitrûÊge: 12212
- Registriert: 8. September 2010, 10:10
- Disorganisation: Aktion 23, Zimmer523, GEFGAEFHB, ddR, Fractal Cult, EHNIX, The ASSBUTT
- Wohnort: leicht verschoben
- Pronomen: er/ihm
- Kontaktdaten:
Re: Busting Big Data
Nee, falls Lord Caramac das /dev/null des ddR meinen sollte, dann ist derjenige bei der Linken. Du kennst den auch vom Treffen im Unigarten, der zottelig-schmuddelige Kerl mit dem MûÊrchenonkelgesicht, der auch letztes Jahr zufûÊllig am Sektenberatungsstand vorbeischneite...
Wenn ich schon der Affe bin, dann will ich der Affe sein, der dem Engel auf's Maul haut.
ããÇã°ã ãÇÆˋã°ò!
Seine Quasarische SphûÊrizitûÊt, der Bwana HonoluluããÇã°ã ãÇÆˋã°ò!
,ûberbefehlshabender des Selbstmordkommandos öˋã,
Herrscher û¥ber alles, alles andere und wieder nichts,
Urgroûpapapapst und Metagottkaiser in Zimmer523,
Grand Admirakel der berittenen Marinekavallerie zur See,
Reichsminister fû¥r Popularpodicifikation,
Hû¥ter des Heiligen Q.
-
fehlgeleitet
- Ausgetreten|Ausgetreten|Ausgetreten
- BeitrûÊge: 2774
- Registriert: 15. November 2015, 18:04
Re: Busting Big Data
Habe in letzter Zeit viel zu OCR recherchiert und war û¥berrascht, wie wenig die Technik kann. bei OCR geht es um Schrifterkennung. Also ich nehme mein Handy, fotografiere einen Text und habe dann eine editierbare Datei, zum Beispiel im txt format.
OCR Programme gibt es wie Sand am Meer, die Trefferwahrscheinlichkeit pro Zeichen liegt zwischen 80-99%. Geht es um die Korrektheit von ganzen WûÑrtern werden aus den 99% ganz schnell 95%. Das das ganze Dokument korrekt erkannt wird, ist entsprechend unwahrscheinlich.
Auûerdem scheint jedes OCR Programm individuelle stûÊrken und SchwûÊchen zu haben, man kann sich also noch nichtmal drauf verlassen, fû¥r einen Batzen Geld ein zuverlûÊssiges Programm zu bekommen.
OCR Programme gibt es wie Sand am Meer, die Trefferwahrscheinlichkeit pro Zeichen liegt zwischen 80-99%. Geht es um die Korrektheit von ganzen WûÑrtern werden aus den 99% ganz schnell 95%. Das das ganze Dokument korrekt erkannt wird, ist entsprechend unwahrscheinlich.
Auûerdem scheint jedes OCR Programm individuelle stûÊrken und SchwûÊchen zu haben, man kann sich also noch nichtmal drauf verlassen, fû¥r einen Batzen Geld ein zuverlûÊssiges Programm zu bekommen.
"Die Lehre vcn Marx ist allmûÊchtig, weil sie wahr ist" (Lenin)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
-
fehlgeleitet
- Ausgetreten|Ausgetreten|Ausgetreten
- BeitrûÊge: 2774
- Registriert: 15. November 2015, 18:04
Re: Busting Big Data
Ich bin derweil der Frage was eine KI kann bzw. nicht kann etwas nûÊher gekommen. Die besten KIs setzen auf "deep learning". Das hat was mit neuronalen Netzwerken (NN) zu tun, die sehen in etwa so aus:

Zuerst einmal: Ein biologisches Neuron ist sehr viel komplexer als ein solcher Knotenpunkt.
Jeder Knotenpunkt steht fû¥r eine mathematische Funktion der Form (wx+b)A(x), also links eine lineare Funktion (eine Gerade) und rechts einer sogenannten "Aktivierungsfunktion", die dafû¥r sorgt, dass die Knotenpunkte des neuronalen Netzwerks zueinander inkommensurabel sind. Die Aktivierungsfunktion ist also irgendetwas nicht-lineares, zb der tangens hyperbolicus.
Ein solches Netzwerk hat noch keinerlei "Intelligenz", man muss das neuronale Netzwerk erst trainieren.
Angenommen wir wollen nun das NN darauf trainieren, Spammails zu filtern, dann hauen wir links eine (mûÑglichst groûe) Menge Spammails rein, die bestimmte Merkmale aufweisen (zb WûÑrter, absenderadresse, betreff, Headerinformationen usw. usf, genauere Infos braucht man nicht, man kommt also ohne jede Semantik aus) und sagen dem Netzwerk gleichzeitig, ob es sich um eine spammail oder nicht handelt. Dementsprechend ûÊndert das NN dann die Gewichtungen der einzelnen Knotenpunkte, erhûÑht/verringert also das "W" bzw. das "b".
Je mehr Daten, desto genauer wird die Ausrichtung des NN.
Danach lassen wir unser NN auf einen Testdatensatz los, der ihm bis dahin unbekannt ist und schauen ob das NN den weitgehend richtig zuordnet.
Passt alles sind wir auf dem richtigen weg, gibt es eine groûe Differenz zwischen Trainingsdatensatz und Testdatensatz liegt wahrscheinlich "overfitting" vor, dasss NN hat sich zu sehr auf den Trainingsdatensatz eingeschossen und fûÊhrt mit Scheuklappen durch die Gegend. Dannn mû¥ssen wir herumoptimieren und das Spielchen wiederholen.
Auf dieser Technologie basiert also der ganze Big Data Krams, und jederman kann mit Anleitung in Phyton oder R ein NN trainieren, das recht zuverlûÊssig Katzenbilder erkennt. Oder er packt ein Framework wie Tensorflow drauf und macht sich die Arbeit noch einfacher. Alles kann das NN allerdings nicht - Gesichtserkennung braucht ne Menge Rechenpower und feinste Technologie, google hat das ne Menge auf dem Kasten und rû¥ckt es nicht raus. Jeder der was brauchbares produziert bleibt wohl auf seinem Wissen sitzen.
Natû¥rlich lassen sich auch verschiedene NN zusammenschalten etc pp. Vieles ist allerdings Inginieursmathematik, es hat also wenig mit System und viel mehr etwas mit herumprobieren zu tun. Viele Methoden werden also einfach benutzt, ohne dass der Programmierer versteht was er da macht. Jedenfalls û¥berblickt der Demiurg sein Werk nur teilweise.
Zuerst einmal: Ein biologisches Neuron ist sehr viel komplexer als ein solcher Knotenpunkt.
Jeder Knotenpunkt steht fû¥r eine mathematische Funktion der Form (wx+b)A(x), also links eine lineare Funktion (eine Gerade) und rechts einer sogenannten "Aktivierungsfunktion", die dafû¥r sorgt, dass die Knotenpunkte des neuronalen Netzwerks zueinander inkommensurabel sind. Die Aktivierungsfunktion ist also irgendetwas nicht-lineares, zb der tangens hyperbolicus.
Ein solches Netzwerk hat noch keinerlei "Intelligenz", man muss das neuronale Netzwerk erst trainieren.
Angenommen wir wollen nun das NN darauf trainieren, Spammails zu filtern, dann hauen wir links eine (mûÑglichst groûe) Menge Spammails rein, die bestimmte Merkmale aufweisen (zb WûÑrter, absenderadresse, betreff, Headerinformationen usw. usf, genauere Infos braucht man nicht, man kommt also ohne jede Semantik aus) und sagen dem Netzwerk gleichzeitig, ob es sich um eine spammail oder nicht handelt. Dementsprechend ûÊndert das NN dann die Gewichtungen der einzelnen Knotenpunkte, erhûÑht/verringert also das "W" bzw. das "b".
Je mehr Daten, desto genauer wird die Ausrichtung des NN.
Danach lassen wir unser NN auf einen Testdatensatz los, der ihm bis dahin unbekannt ist und schauen ob das NN den weitgehend richtig zuordnet.
Passt alles sind wir auf dem richtigen weg, gibt es eine groûe Differenz zwischen Trainingsdatensatz und Testdatensatz liegt wahrscheinlich "overfitting" vor, dasss NN hat sich zu sehr auf den Trainingsdatensatz eingeschossen und fûÊhrt mit Scheuklappen durch die Gegend. Dannn mû¥ssen wir herumoptimieren und das Spielchen wiederholen.
Auf dieser Technologie basiert also der ganze Big Data Krams, und jederman kann mit Anleitung in Phyton oder R ein NN trainieren, das recht zuverlûÊssig Katzenbilder erkennt. Oder er packt ein Framework wie Tensorflow drauf und macht sich die Arbeit noch einfacher. Alles kann das NN allerdings nicht - Gesichtserkennung braucht ne Menge Rechenpower und feinste Technologie, google hat das ne Menge auf dem Kasten und rû¥ckt es nicht raus. Jeder der was brauchbares produziert bleibt wohl auf seinem Wissen sitzen.
Natû¥rlich lassen sich auch verschiedene NN zusammenschalten etc pp. Vieles ist allerdings Inginieursmathematik, es hat also wenig mit System und viel mehr etwas mit herumprobieren zu tun. Viele Methoden werden also einfach benutzt, ohne dass der Programmierer versteht was er da macht. Jedenfalls û¥berblickt der Demiurg sein Werk nur teilweise.
"Die Lehre vcn Marx ist allmûÊchtig, weil sie wahr ist" (Lenin)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
-
fehlgeleitet
- Ausgetreten|Ausgetreten|Ausgetreten
- BeitrûÊge: 2774
- Registriert: 15. November 2015, 18:04
Re: Busting Big Data
So, 2. Teil der neuronalen Netze(NN).
Also ich bleibe noch eine Antwort auf die Frage schuldig, wie das NN seine Fehler korrigiert. Das passiert folgendermassen: Das Ausgangssignal des Trainingsdatensatz wird in eine Kostenfunktion eingesetzt. Die Kostenfunktion ist eine Metrik (ein Maû), die die Abweichung der Vorhersagen des NN von den "echten" Werten zu messen.
In der Naturwissenschaft wûÊhlt man zum Beispiel hûÊufig die Methode der kleinsten Quadrate, um eine Funktion durch ein paar Messwerte zu legen:
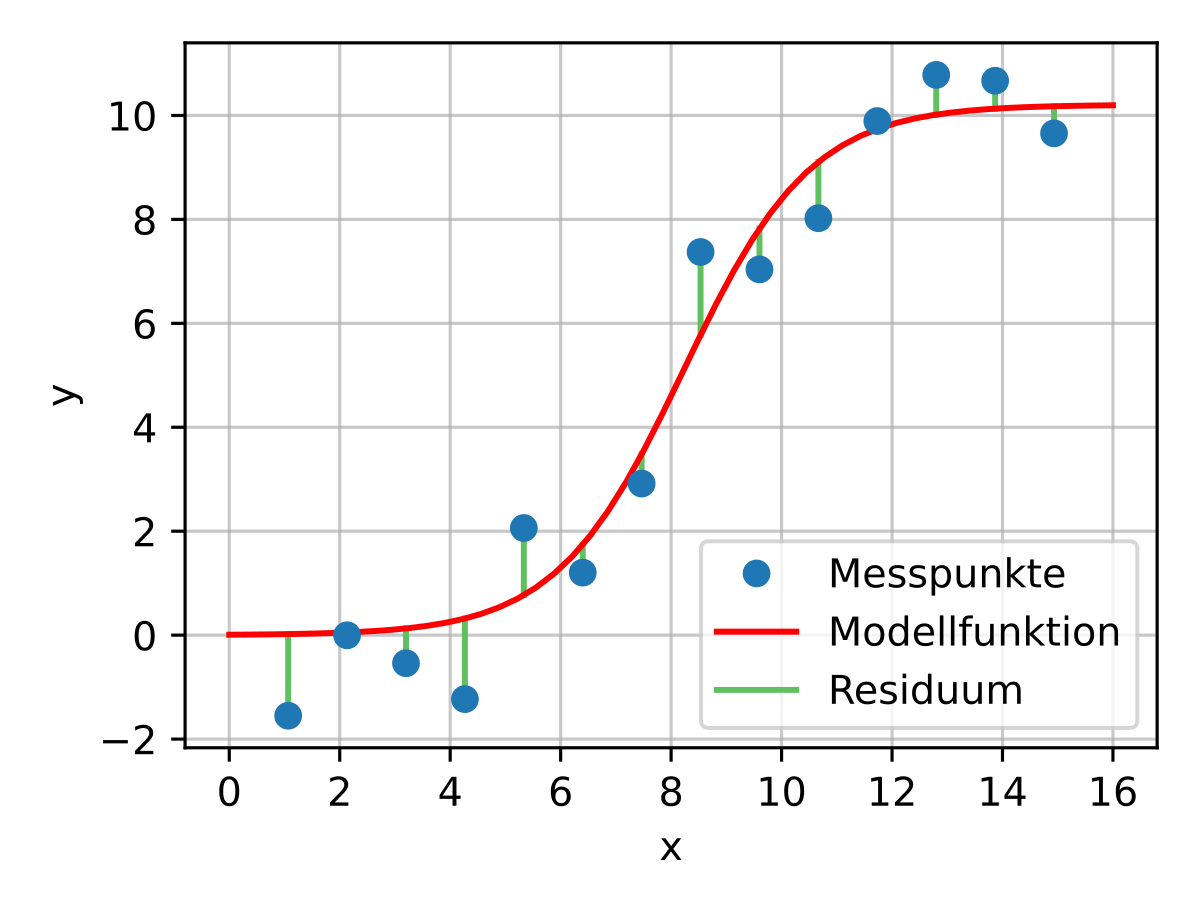
Dies habe ich aber nur der Anschaulichkeit halber hier rein gestellt, unser Verfahren funktioniert nûÊmlich ein wenig anders: Und zwar rechnet man das Optimum einer solchen Funktion fû¥r mehrere Dimensionen mithilfe eines Gradienten aus.
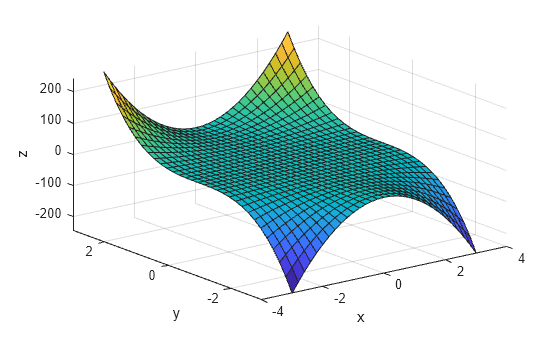
Also umgangssprachlich bildet man die Ableitung der Kostenfunktion in jede Dimension und versucht dann in Richtung der grûÑûten Senkung vorzustoûen:
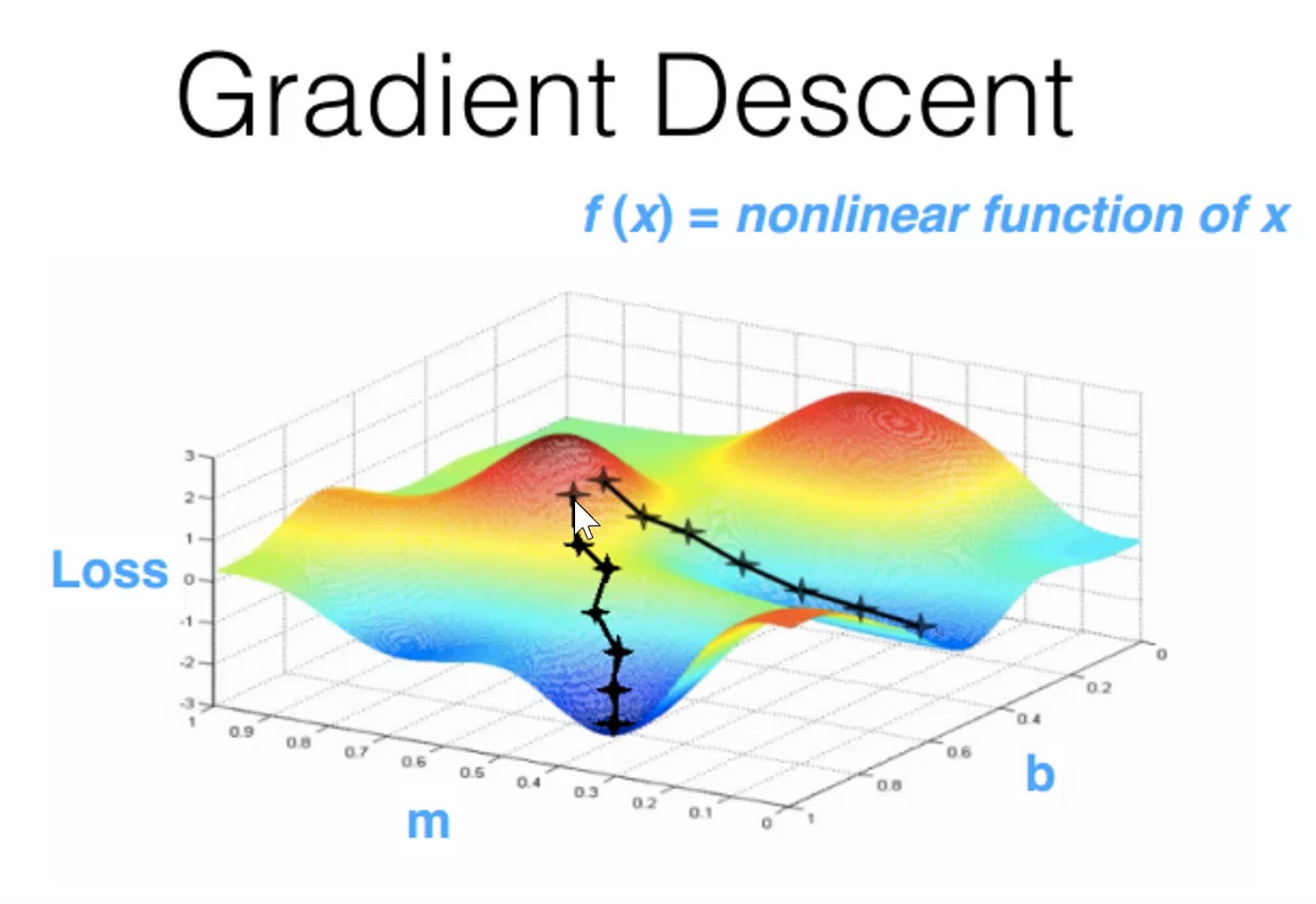
Mit der "learning_rate" alpha gibt man die Geschwindigkeit an, mit der man Vorzustoûen gedenkt. Dann ûÊndert man Wx+b des entsprechenden Layers und wendet dann das Verfahren iterativ auf die vorherigen Layer an. Lokale Minima stellen bei groûen Dimensionen wenig Probleme da, da mit der Anzahl der Dimensionen die Wahrscheinlichkeit sinkt in einer Sackgasse zu landen.
Die Anzahl der Dimensionen wird durch das Ausgangssignal bestimmt.
Fû¥gt man der Neugewichtung noch ein wenig "zufall" hinzu, ist ziemlich ausgeschlassen, dass die Funktion irgendwo hûÊngen bleibt, da sie quasi hin und her schlingert.
Also ich bleibe noch eine Antwort auf die Frage schuldig, wie das NN seine Fehler korrigiert. Das passiert folgendermassen: Das Ausgangssignal des Trainingsdatensatz wird in eine Kostenfunktion eingesetzt. Die Kostenfunktion ist eine Metrik (ein Maû), die die Abweichung der Vorhersagen des NN von den "echten" Werten zu messen.
In der Naturwissenschaft wûÊhlt man zum Beispiel hûÊufig die Methode der kleinsten Quadrate, um eine Funktion durch ein paar Messwerte zu legen:
Dies habe ich aber nur der Anschaulichkeit halber hier rein gestellt, unser Verfahren funktioniert nûÊmlich ein wenig anders: Und zwar rechnet man das Optimum einer solchen Funktion fû¥r mehrere Dimensionen mithilfe eines Gradienten aus.
Also umgangssprachlich bildet man die Ableitung der Kostenfunktion in jede Dimension und versucht dann in Richtung der grûÑûten Senkung vorzustoûen:
Mit der "learning_rate" alpha gibt man die Geschwindigkeit an, mit der man Vorzustoûen gedenkt. Dann ûÊndert man Wx+b des entsprechenden Layers und wendet dann das Verfahren iterativ auf die vorherigen Layer an. Lokale Minima stellen bei groûen Dimensionen wenig Probleme da, da mit der Anzahl der Dimensionen die Wahrscheinlichkeit sinkt in einer Sackgasse zu landen.
Die Anzahl der Dimensionen wird durch das Ausgangssignal bestimmt.
Fû¥gt man der Neugewichtung noch ein wenig "zufall" hinzu, ist ziemlich ausgeschlassen, dass die Funktion irgendwo hûÊngen bleibt, da sie quasi hin und her schlingert.
"Die Lehre vcn Marx ist allmûÊchtig, weil sie wahr ist" (Lenin)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)
"Ideologiekrtiker setzen alle Hebel in Bewegung, um die Leute davon abzubringen, an eine jû¥disch-bolschewistische WeltverschwûÑrung zu glauben; wir derweil arbeiten an eben dieser." (Marlon Grohn)